Das ist eine für den Ausdruck optimierte Ansicht des gesamten Kapitels inkl. Unterseiten. Druckvorgang starten.
Blog
- Artikel
- Die Brücke zwischen Business und IT
- Was man alles mit Klartext-Formaten machen kann
- Rollenkonzepte im EAM
- Once-Only in Dokumentationen
- Mehrere Wege einen Datenfluss zu modellieren
- Portfolios in EAM
- EVA-Prinzip im Zusammenhang mit EAM
- Neuigkeiten
Artikel
Die Brücke zwischen Business und IT
Informationssystemarchitektur - Die Brücke zwischen Business und IT
Die Informationssystemarchitektur (ISA) bildet das zentrale Bindeglied zwischen Geschäftsanforderungen und technologischer Umsetzung. Sie übersetzt fachliche Anforderungen aus der Geschäftsarchitektur in konkrete Informationssysteme und stellt gleichzeitig sicher, dass diese effizient auf der IT-Infrastruktur betrieben werden können.
Im Kontext des Enterprise Architecture Managements (EAM) nimmt sie eine Schlüsselrolle ein: Sie verbindet Geschäftsprozesse, Daten und Anwendungen zu einem konsistenten Gesamtbild der IT-Landschaft.
flowchart TD id1(Geschäftsarchitektur) <--Was? Wie?--> id2(Informationssystemarchitektur) <--Womit?--> id3(Technische Architektur) style id1 fill:#ffffee,stroke:#eeeeee,stroke-width:2px style id2 fill:#00ffff,stroke:#000000,stroke-width:2px style id3 fill:#eeffee,stroke:#eeeeee,stroke-width:2px
Was versteht man genau darunter?
Die Informationssystemarchitektur beschreibt die Struktur, Beziehungen und Interaktionen von Informationssystemen innerhalb eines Unternehmens.
Sie beantwortet zentrale Fragestellungen wie:
- Welche Anwendungen unterstützen welche Geschäftsprozesse?
- Welche Daten werden wo verarbeitet?
- Wie interagieren Systeme miteinander?
- Welche Abhängigkeiten bestehen?
EAM liefert hierfür den methodischen Rahmen: Es ermöglicht eine ganzheitliche Sicht auf Business und IT, um Komplexität zu beherrschen und fundierte Entscheidungen zu treffen.
Ziel der Informationssystemarchitektur
- Transparenz über die IT-Landschaft schaffen
- Business-IT-Alignment sicherstellen
- Redundanzen und Komplexität reduzieren
- Grundlage für strategische IT-Planung liefern
Ein zentrales Problem vieler Organisationen ist eine historisch gewachsene, heterogene Systemlandschaft mit redundanten Funktionen und unüberschaubaren Schnittstellen.
Wie kann man die IS-Architektur unterteilen?
Die Informationssystemarchitektur lässt sich in mehrere eng miteinander verknüpfte Teilbereiche gliedern:
flowchart LR A(Daten / Informationen) --> B(Applikationen) B --> C(Integration) C --> A
Daten/Informationen
Die Datenarchitektur beschreibt die fachlichen und technischen Datenstrukturen eines Unternehmens.
Zentrale Aspekte:
- Geschäftsobjekte (z. B. Kunde, Auftrag)
- Datenmodelle und Datenflüsse
- Datenqualität und -verantwortung
- Datenschutz und Schutzbedarf
Daten sind die Grundlage der Informationssysteme – ohne konsistente Datenbasis ist keine stabile Architektur möglich.
Ziel: „Single Source of Truth“ und Vermeidung von Redundanzen
Anwendungen/Applikationen
Die Applikationsarchitektur beschreibt die Gesamtheit der eingesetzten Informationssysteme und deren fachliche Zuordnung.
Typische Elemente:
- Fachanwendungen (z. B. ERP, CRM)
- Services / Microservices
- Legacy-Systeme
- Applikationslandschaft (Application Landscape)
Ein wesentliches Ziel ist die Beherrschung der Systemvielfalt, da zu viele Anwendungen mit ähnlichen Funktionen zu steigender Komplexität und Kosten führen.
Ziel: Konsolidierung und klare Verantwortlichkeiten
Integration
Die Integrationsarchitektur beschreibt, wie Anwendungen miteinander kommunizieren.
flowchart TD A(System A) -->|API| B(Integration Layer) B -->|Event| C(System B) B -->|Batch| D(System C)
Typische Integrationsformen:
- APIs (REST, GraphQL)
- Messaging / Events
- ETL / Batch-Verarbeitung
- Middleware / ESB
Integration ist einer der kritischsten Aspekte, da hier häufig die größte Komplexität entsteht (Schnittstellenwildwuchs).
Ziel: Lose Kopplung und standardisierte Schnittstellen
Architekturprinzipien & Governance
In der Praxis ist die Informationssystemarchitektur ohne klare Leitplanken nicht steuerbar.
Typische Prinzipien:
- Standardisierung vor Individualisierung
- Wiederverwendung vor Neuentwicklung
- API-First / Serviceorientierung
- Cloud-Readiness
Governance-Elemente:
- Architektur-Reviews
- Zielarchitekturen und Roadmaps
- Technologiestandards
EAM stellt sicher, dass diese Prinzipien systematisch angewendet und kontrolliert werden.
Wie wird die Verbindung zu Business und IT-Infrastruktur sichergestellt?
Die Informationssystemarchitektur wirkt in zwei Richtungen:
1. Verbindung zum Business
flowchart TD A(Geschäftsprozess) --> B(Informationssystem) B --> C(Datenobjekte)
- Geschäftsprozesse definieren Anforderungen
- Informationssysteme setzen diese um
- Daten bilden die fachliche Grundlage
So lässt sich z. B. analysieren:
„Welche Systeme unterstützen welchen Prozess?“_
2. Verbindung zur IT-Infrastruktur
flowchart TD A(Informationssystem) --> B(Plattform) B --> C(Infrastruktur)
- Anwendungen laufen auf Plattformen
- Plattformen nutzen Infrastruktur (Cloud, Netzwerk, Hardware)
- Technische Architektur stellt Betrieb sicher
Zentrale Mechanismen für das Alignment
- Transparenz durch Visualisierung (z. B. Bebauungspläne)
- Verknüpfung von Business- und IT-Objekten
- Zielarchitektur und Roadmaps
- Kontinuierliche Analyse der Abhängigkeiten
EAM ermöglicht hier eine integrierte Sicht auf alle Architekturdimensionen und macht Zusammenhänge sichtbar.
Fazit
Die Informationssystemarchitektur ist weit mehr als eine technische Disziplin – sie ist das zentrale Steuerungsinstrument für die IT-Landschaft.
Sie:
- verbindet Business und IT
- schafft Transparenz und Entscheidungsgrundlagen
- reduziert Komplexität
- ermöglicht strategische Weiterentwicklung
Ohne eine klare Informationssystemarchitektur droht:
- unkontrolliertes Wachstum der IT-Landschaft
- steigende Kosten und Risiken
- fehlende strategische Steuerbarkeit
Mit einer etablierten ISA hingegen entsteht eine tragfähige Brücke zwischen Geschäftsstrategie und technologischer Umsetzung – und damit die Grundlage für eine erfolgreiche digitale Transformation.
Was man alles mit Klartext-Formaten machen kann
Einführung in die Klartext-Welt
Digitale Inhalte entstehen heute in den unterschiedlichsten Formen: Webseiten, Dokumentationen, Präsentationen oder technische Diagramme. Traditionell werden solche Inhalte häufig mit grafischen Werkzeugen erstellt – etwa mit Word, PowerPoint oder Zeichenprogrammen. Diese Werkzeuge sind intuitiv, haben aber einen entscheidenden Nachteil: Die Inhalte liegen meist in proprietären Dateiformaten vor und lassen sich nur schwer automatisieren, versionieren oder weiterverarbeiten.
Eine Alternative dazu sind Klartext-Formate (Plain Text). Dabei werden Inhalte nicht visuell, sondern über eine einfache, textbasierte Syntax beschrieben. Diese Dateien lassen sich mit jedem Texteditor bearbeiten, einfach versionieren und automatisiert weiterverarbeiten.
Gerade in der Softwareentwicklung, im DevOps-Umfeld und in modernen Dokumentationsprozessen hat sich daher ein Ansatz etabliert, der oft als „Documentation as Code“ bezeichnet wird: Inhalte werden wie Quellcode behandelt – in Klartext geschrieben, in Git versioniert und automatisch veröffentlicht.
Was genau sind Klartext-Formate?
Klartext-Formate sind Dateiformate, deren Inhalt aus normal lesbarem Text besteht. Sie benötigen keine spezielle Software, um gelesen zu werden, sondern können mit jedem einfachen Editor geöffnet werden.
Typische Eigenschaften von Klartext-Formaten sind:
-
Lesbarkeit für Menschen – auch ohne spezielle Software
-
Einfache Struktur durch leichte Markup-Syntax
-
Versionskontrolle mit Systemen wie Git
-
Automatisierbarkeit durch Build-Pipelines
-
Portabilität über verschiedene Systeme hinweg
Ein Beispiel ist eine einfache Markdown-Datei:
# Titel
Dies ist ein Absatz.
- Punkt 1
- Punkt 2
Der Text bleibt lesbar, auch wenn er noch nicht gerendert wurde.
Diese Eigenschaft unterscheidet Klartextformate grundlegend von Formaten wie .docx, .pptx oder .vsdx, die intern komplexe XML-Strukturen enthalten und nur mit spezieller Software sinnvoll bearbeitet werden können.
Welche Formate gibt es?
Klartextformate lassen sich grob in zwei Kategorien einteilen:
-
Formate zur Strukturierung von Text
-
Formate zur Beschreibung von Visualisierungen
Beide folgen dem gleichen Prinzip: Inhalte werden über eine einfache Syntax beschrieben und anschließend automatisch gerendert.
Formate für Textverarbeitung
Markdown
Markdown ist das vermutlich am weitesten verbreitete Klartextformat. Es wurde entwickelt, um Text möglichst einfach zu strukturieren, ohne die Lesbarkeit zu beeinträchtigen.
Typische Einsatzgebiete sind:
-
README-Dateien
-
technische Dokumentationen
-
Webseiten
-
Wissensdatenbanken
Markdown verwendet eine sehr einfache Syntax:
# Überschrift
## Unterüberschrift
**Fett**
*kursiv*
- Liste
- Liste
Die Stärke von Markdown liegt in seiner Einfachheit und breiten Unterstützung. Plattformen wie GitHub, GitLab oder viele CMS-Systeme unterstützen Markdown direkt.
Der Nachteil: Die Funktionalität ist bewusst begrenzt. Komplexere Dokumentstrukturen sind damit schwieriger umzusetzen.
AsciiDoc
AsciiDoc ist ein deutlich mächtigeres Textformat als Markdown. Es richtet sich vor allem an technische Dokumentation und umfangreiche Inhalte.
Im Vergleich zu Markdown bietet AsciiDoc unter anderem:
-
komplexe Dokumentstrukturen
-
Inhaltsverzeichnisse
-
Referenzen
-
Tabellen
-
Variablen und Attribute
-
erweiterbare Funktionen
Beispiel:
= Dokumenttitel
Autor
:toc:
== Kapitel
Ein Absatz.
=== Unterkapitel
* Liste
* Liste
AsciiDoc eignet sich besonders für:
-
umfangreiche technische Dokumentation
-
Handbücher
-
Bücher
-
Architektur-Dokumentationen
Gerade in Verbindung mit Tools wie Antora oder Asciidoctor lassen sich daraus sehr professionelle Dokumentationsportale generieren.
Weitere bekannte Formate
Neben Markdown und AsciiDoc existieren noch weitere textbasierte Markup-Sprachen:
reStructuredText (reST)
Wird häufig im Python-Ökosystem verwendet, etwa für Dokumentationen mit Sphinx.
Org Mode
Ein sehr leistungsfähiges Format aus dem Emacs-Umfeld, das Notizen, Aufgabenverwaltung und Dokumentation kombiniert.
LaTeX
Ein wissenschaftlich geprägtes Textsatzsystem, das besonders für mathematische Inhalte und wissenschaftliche Publikationen verwendet wird.
Textile
Ein älteres Markup-Format, das früher in vielen Wikis eingesetzt wurde.
Formate für Visualisierung
Neben Text können auch Diagramme und Visualisierungen in Klartext beschrieben werden.
Dabei wird nicht gezeichnet, sondern die Struktur eines Diagramms textuell beschrieben.
Mermaid
Mermaid ist eine weit verbreitete Sprache zur Erstellung von Diagrammen in Klartext. Sie wird inzwischen von vielen Plattformen direkt unterstützt, darunter GitHub, GitLab und zahlreiche Dokumentationssysteme.
Ein einfaches Beispiel:
graph TD
A[Start] --> B{Entscheidung}
B -->|Ja| C[Aktion]
B -->|Nein| D[Ende]
Das ergibt:
graph TD
A[Start] --> B{Entscheidung}
B -->|Ja| C[Aktion]
B -->|Nein| D[Ende]
Mermaid unterstützt unter anderem:
-
Flowcharts
-
Sequenzdiagramme
-
Gantt-Diagramme
-
State-Diagramme
-
ER-Diagramme
Der große Vorteil von Mermaid ist die einfache Syntax und breite Integration in moderne Dokumentationsplattformen.
PlantUML
PlantUML ist eine leistungsfähige Sprache zur Beschreibung von UML-Diagrammen und vielen weiteren Diagrammtypen.
Beispiel für ein Sequenzdiagramm:
@startuml
Alice -> Bob: Anfrage
Bob --> Alice: Antwort
@enduml
Das ergibt:

PlantUML unterstützt:
-
UML-Diagramme
-
Sequenzdiagramme
-
Komponenten-Diagramme
-
Deployment-Diagramme
-
C4-Modelle
-
Architekturdiagramme
PlantUML ist besonders im Architektur- und Softwaredesign-Kontext sehr beliebt.
Weitere bekannte Formate
Neben Mermaid und PlantUML existieren noch weitere textbasierte Visualisierungssprachen:
Graphviz / DOT
Eine der ältesten Diagrammbeschreibungssprachen für Graphen.
D2
Eine moderne Diagrammsprache mit Fokus auf einfache Lesbarkeit.
Structurizr DSL
Eine Sprache speziell zur Beschreibung von Architekturdiagrammen nach dem C4-Modell.
TikZ
Eine sehr leistungsfähige Diagrammsprache aus der LaTeX-Welt.
Möglichkeiten Anwendungen
Klartextformate sind extrem vielseitig und lassen sich in vielen Bereichen einsetzen.
Notizen
Viele moderne Notizsysteme basieren auf Markdown oder ähnlichen Formaten. Beispiele sind Wissenssysteme, persönliche Wikis oder strukturierte Notizen.
Der Vorteil: Notizen bleiben langfristig lesbar und unabhängig von einer bestimmten Software.
Webseiten
Viele moderne Webseiten werden aus Klartextformaten generiert. Statische Site Generatoren verwandeln Markdown- oder AsciiDoc-Dateien automatisch in HTML-Seiten.
Bekannte Tools sind:
-
Hugo
-
Jekyll
-
MkDocs
-
Antora
Dieses Prinzip wird häufig für Dokumentationswebseiten und Blogs verwendet.
Dokumente
Auch klassische Dokumente lassen sich aus Klartext generieren:
-
PDF
-
Word
-
HTML
-
Präsentationen
Tools wie Pandoc ermöglichen die Konvertierung zwischen zahlreichen Formaten.
Dokumentationen
Technische Dokumentationen profitieren besonders stark von Klartextformaten.
Sie ermöglichen:
-
Versionsverwaltung
-
Zusammenarbeit über Git
-
automatische Builds
-
strukturierte Dokumentationsportale
Dieser Ansatz wird häufig als Docs-as-Code bezeichnet.
Bücher / eBooks
Viele Bücher werden heute aus Klartextquellen erzeugt. Der gleiche Inhalt kann dabei in verschiedene Ausgabeformate transformiert werden:
-
PDF
-
EPUB
-
HTML
Gerade im technischen Bereich ist dieser Ansatz sehr verbreitet.
Präsentationen
Auch Präsentationen lassen sich heute vollständig aus Klartextformaten erzeugen. Statt Folien direkt in Programmen wie PowerPoint oder Keynote zu gestalten, wird der Inhalt zunächst in einer textbasierten Beschreibungssprache geschrieben und anschließend automatisch in eine Präsentation umgewandelt.
Ein einfaches Beispiel in Markdown könnte so aussehen:
# Titel der Präsentation
---
## Problemstellung
- Punkt 1
- Punkt 2
---
## Lösung
Ein strukturierter Ansatz.
Spezialisierte Präsentations-Frameworks interpretieren diese Struktur und generieren daraus fertige Folien.
Typische Werkzeuge sind:
-
Reveal.js – ein sehr verbreitetes HTML-Präsentationsframework, das häufig mit Markdown kombiniert wird
-
Marp – ein Markdown-basiertes Präsentationssystem mit Fokus auf einfache Erstellung und Export nach PDF oder PowerPoint
-
Slidev – ein modernes Präsentationsframework für Entwickler, basierend auf Markdown und Vue.js
-
Pandoc – kann Markdown oder AsciiDoc in Präsentationsformate wie Reveal.js oder Beamer konvertieren
Ein Vorteil dieses Ansatzes liegt darin, dass Präsentationen genauso behandelt werden können wie Quellcode oder Dokumentation:
-
Inhalte sind versionierbar
-
Änderungen lassen sich nachvollziehen
-
Präsentationen können automatisch generiert werden
-
Inhalte lassen sich leicht wiederverwenden
Gerade in technischen Umgebungen wird dieser Ansatz zunehmend verwendet, beispielsweise für:
-
Architekturpräsentationen
-
technische Schulungen
-
Konferenzvorträge
-
Projektvorstellungen
Da die Präsentationen auf Klartext basieren, lassen sie sich außerdem leicht mit anderen Artefakten kombinieren – etwa mit automatisch generierten Diagrammen aus PlantUML oder Mermaid.
Bilder
Auch Bilder und Diagramme können aus Klartext generiert werden, beispielsweise:
-
Architekturdiagramme
-
Prozessdiagramme
-
UML-Diagramme
Der Vorteil: Änderungen können einfach im Text vorgenommen und versioniert werden.
Nützliche Tools
Die Arbeit mit Klartextformaten wird durch eine Vielzahl von Werkzeugen unterstützt.
Texteditoren
Grundsätzlich reicht bereits ein einfacher Editor aus. Besonders komfortabel sind jedoch spezialisierte Editoren mit Syntax-Hervorhebung und Vorschau.
Beliebte Beispiele sind:
-
Visual Studio Code
-
Obsidian
-
Typora
-
Sublime Text
Viele dieser Tools unterstützen Plugins für Markdown, AsciiDoc, Mermaid oder PlantUML.
Konverter
Konverter ermöglichen die Transformation zwischen verschiedenen Dokumentformaten.
Ein besonders mächtiges Werkzeug ist Pandoc, das hunderte Formate miteinander konvertieren kann.
Typische Konvertierungen sind:
-
Markdown → PDF
-
Markdown → Word
-
AsciiDoc → HTML
-
Markdown → Präsentation
Versionsverwaltung
Ein großer Vorteil von Klartextformaten ist ihre Integration mit Versionsverwaltungssystemen.
Mit Tools wie Git lassen sich Änderungen:
-
nachvollziehen
-
vergleichen
-
gemeinsam bearbeiten
-
automatisiert veröffentlichen
Gerade für Dokumentationsteams ist dies ein großer Vorteil gegenüber klassischen Office-Dokumenten.
Fazit
Klartextformate bieten eine flexible und zukunftssichere Grundlage für die Erstellung digitaler Inhalte. Sie ermöglichen es, Texte, Dokumentationen und Diagramme auf einfache Weise zu strukturieren und automatisiert weiterzuverarbeiten.
Durch ihre Lesbarkeit, Offenheit und gute Integrationsfähigkeit passen sie hervorragend in moderne Entwicklungs- und Dokumentationsprozesse.
Wer Inhalte langfristig wartbar, versionierbar und automatisierbar gestalten möchte, findet in Klartextformaten eine leistungsfähige Alternative zu klassischen Office-Werkzeugen.
Rollenkonzepte im EAM
Rollen-Konzepte im EAM
Wozu Rollen im EAM?
Enterprise Architecture Management (EAM) bewegt sich im Spannungsfeld zwischen Strategie, Organisation, IT-Systemen und operativen Prozessen. Ohne klar definierte Rollen besteht die Gefahr, dass Architekturarbeit entweder rein dokumentarisch bleibt oder unkoordiniert von verschiedenen Stellen betrieben wird.
Rollen im EAM erfüllen daher mehrere zentrale Funktionen:
1. Verantwortlichkeiten klären
Architekturentscheidungen betreffen viele Bereiche eines Unternehmens. Rollen sorgen dafür, dass klar ist, wer Entscheidungen vorbereitet, trifft oder verantwortet.
2. Perspektiven strukturieren
EAM betrachtet Organisationen aus unterschiedlichen Blickwinkeln (Business, Daten, Anwendungen, Technologie). Rollen helfen, diese Perspektiven organisatorisch zu verankern.
3. Kommunikation ermöglichen
Architektur ist ein Übersetzungsraum zwischen Business und IT. Rollen definieren, wer welche Sprache spricht und welche Interessen vertritt.
4. Governance sicherstellen
Architekturvorgaben entfalten nur Wirkung, wenn jemand für ihre Durchsetzung zuständig ist – etwa über Architekturboards oder Review-Prozesse.
Kurz gesagt:
Rollen bilden die organisatorische Grundlage, damit Architektur nicht nur modelliert, sondern auch gelebt und gesteuert wird.
Wie gehen bekannte Frameworks damit um?
TOGAF
Das TOGAF-Framework definiert eine Reihe von Rollen rund um die Architekturarbeit, insbesondere im Kontext der Architecture Development Method (ADM).
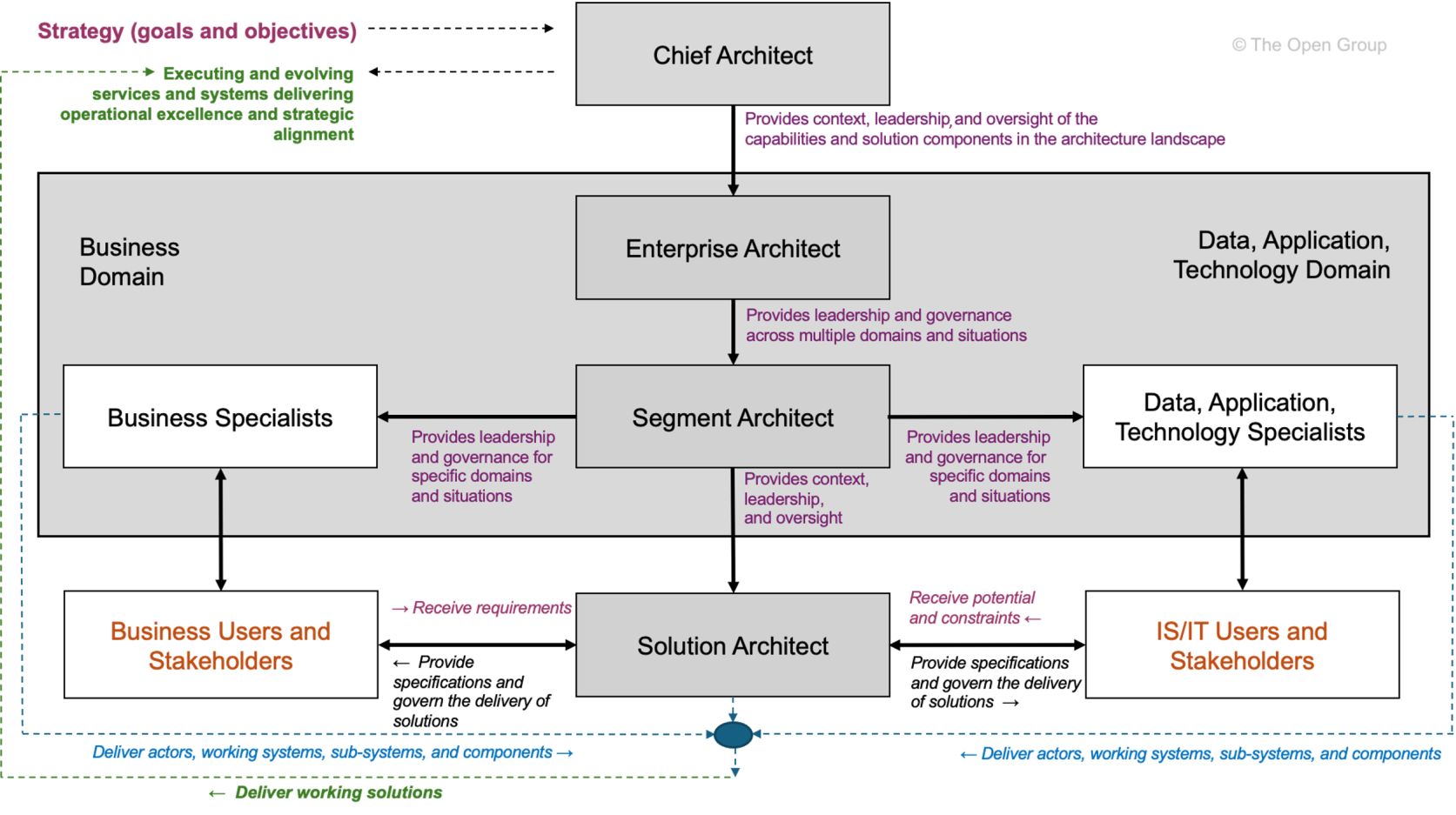 Entnommen von TOGAF Architecture Roles and Skills (Benutzerkonto notwendig).
Entnommen von TOGAF Architecture Roles and Skills (Benutzerkonto notwendig).
Die Architekturrollen in TOGAF sind:
-
Enterprise Architect – Gesamtverantwortung für die Architektur des Unternehmens
-
Segment Architect – Verantwortung für spezifische Architekturdomänen (Business, Data, Application, Technology)
-
Solution Architect – Architektur eines konkreten Projekts oder Systems
-
Chief Architect – Governance- und Entscheidungsorgan für Architekturfragen
TOGAF betrachtet Rollen primär aus einer Governance- und Prozessperspektive.
Sie sind eng mit den Phasen der ADM und der Architektur-Governance verknüpft.
Die Rollen sind jedoch bewusst generisch formuliert und müssen von jeder Organisation an ihre eigene Struktur angepasst werden.
Zachman Framework
Das Zachman Framework verfolgt einen anderen Ansatz. Es definiert keine expliziten Rollen, sondern strukturiert Architekturartefakte entlang zweier Dimensionen:

Bild entnommen von About the Zachman Framework.
-
Fragen (What, How, Where, Who, When, Why)
-
Perspektiven (Planner, Owner, Designer, Builder, Subcontractor, Functioning System)
Die Zeilen des Frameworks lassen sich jedoch als implizite Rollenperspektiven interpretieren:
| Perspektive | Typische Rolle |
|---|---|
| Planner | Strategie / Unternehmensleitung |
| Owner | Business-Verantwortliche |
| Designer | Enterprise- oder Solution-Architekt |
| Builder | Entwickler / Implementierung |
| Subcontractor | technische Spezialisten |
Der Beitrag des Zachman-Frameworks liegt weniger in konkreten Rollenbezeichnungen, sondern in der Erkenntnis:
Architektur entsteht aus unterschiedlichen Perspektiven und Fragestellungen.
Damit liefert Zachman eine gute Grundlage, um Rollen systematisch aus den grundlegenden Architekturfragen abzuleiten.
Rollen im Bezug zum EVA-Prinzip
Das EVA-Prinzip (Eingabe – Verarbeitung – Ausgabe) kann als einfache Denkstruktur verwendet werden, um Verantwortlichkeiten im Architekturkontext zu strukturieren.
Übertragen auf Architekturfragen lassen sich sechs grundlegende Perspektiven unterscheiden:
-
Was – Gegenstände und Informationen
-
Wie – Prozesse und Funktionen
-
Womit – Werkzeuge und Technologien
-
Weshalb – Ziele und Motivation
-
Wann – zeitliche Struktur und Planung
-
Wer – Organisation und Verantwortlichkeiten
Diese Fragen helfen, Rollen nicht nur nach Hierarchie oder Fachdomäne zu definieren, sondern nach ihrer funktionalen Verantwortung im Architekturraum.
Im Zusammenhang mit den Grundfragen
Rollen/Verantwortlichkeiten für das “WAS”
Die Frage nach dem „Was“ bezieht sich auf die zentralen Informationsobjekte einer Organisation.
Typische Verantwortlichkeiten:
-
Definition zentraler Informationsobjekte
-
Datenmodelle und Informationsstrukturen
-
Datenqualität und Datenverantwortung
Typische Rollen:
-
Data Architect
-
Information Architect
-
Data Owner
-
Data Steward
Diese Rollen stellen sicher, dass Datenstrukturen konsistent und organisationsweit verständlich sind.
Rollen/Verantwortlichkeiten für das “WIE”
Das „Wie“ beschreibt die Prozesse und Funktionen, mit denen eine Organisation ihre Leistungen erbringt.
Typische Verantwortlichkeiten:
-
Modellierung von Geschäftsprozessen
-
Definition von Fähigkeiten (Capabilities)
-
Abstimmung zwischen Business und IT
Typische Rollen:
-
Business Architect
-
Process Owner
-
Capability Manager
Diese Rollen sorgen dafür, dass Geschäftsprozesse und IT-Systeme aufeinander abgestimmt sind.
Rollen/Verantwortlichkeiten für das “WOMIT”
Die Frage „Womit“ betrifft die technologischen Mittel zur Umsetzung der Prozesse.
Typische Verantwortlichkeiten:
-
Technologie-Standards
-
Plattformarchitekturen
-
Infrastruktur-Strategien
Typische Rollen:
-
Technology Architect
-
Infrastructure Architect
-
Platform Architect
Sie definieren die technischen Rahmenbedingungen, innerhalb derer Lösungen entstehen.
Im Zusammenhang mit den Grundfragen
Rollen/Verantwortlichkeiten für das “WESHALB”
Das „Weshalb“ verbindet Architektur mit der strategischen Ausrichtung des Unternehmens.
Typische Verantwortlichkeiten:
-
Ableitung von Architekturprinzipien
-
strategische Zielbilder
-
Transformations-Roadmaps
Typische Rollen:
-
Enterprise Architect
-
Strategy Architect
-
Transformation Lead
Diese Rollen sorgen dafür, dass Architekturentscheidungen strategisch begründet sind.
Rollen/Verantwortlichkeiten für das “WANN”
Das „Wann“ betrifft die zeitliche Koordination von Architekturveränderungen.
Typische Verantwortlichkeiten:
-
Transformationsplanung
-
Roadmaps
-
Release- und Programmplanung
Typische Rollen:
-
Portfolio Manager
-
Program Manager
-
Transformation Manager
Sie sorgen dafür, dass Architektur nicht nur entworfen, sondern auch zeitlich umgesetzt wird.
Rollen/Verantwortlichkeiten für das “WER”
Die Frage „Wer“ betrifft die organisatorische Verankerung der Architekturarbeit.
Typische Verantwortlichkeiten:
-
Governance-Strukturen
-
Rollen und Verantwortlichkeiten
-
Entscheidungsprozesse
Typische Rollen:
-
Architecture Board
-
Domain Leads
-
Architecture Governance Lead
Diese Rollen stellen sicher, dass Architekturentscheidungen institutionell verankert sind.
Skalierung des Rollen-Konzeptes
Nicht jede Organisation benötigt dieselben Rollen.
Die Anzahl und Spezialisierung von Rollen hängt stark von der Größe und Komplexität der Organisation ab.
Das DPBoK (Digital Practitioner Body of Knowledge) beschreibt vier Kontextstufen, anhand derer sich Rollen sinnvoll skalieren lassen.
Context I: Einzelperson / Gründer
In sehr kleinen Organisationen übernimmt eine einzelne Person oft mehrere Rollen gleichzeitig.
Typische Situation:
-
Gründer = Strategie, Architektur und Umsetzung
-
geringe formale Trennung von Rollen
Charakteristika:
-
implizite Architektur
-
schnelle Entscheidungen
-
minimale Governance
Architekturarbeit erfolgt hier eher intuitiv.
Context II: Team
Mit zunehmender Größe entstehen erste funktionale Rollen.
Typische Rollen:
-
Product Owner
-
Lead Developer
-
Solution Architect
Architektur entsteht häufig innerhalb eines Teams und wird stark durch konkrete Produkte geprägt.
Context III: Team von Teams
Ab dieser Stufe entstehen koordinierende Architekturrollen.
Typische Rollen:
-
Enterprise Architect
-
Domain Architect
-
Architecture Board
Zentrale Aufgaben:
-
Abstimmung zwischen Teams
-
gemeinsame Architekturprinzipien
-
Plattform- und Datenstandards
Architektur wird hier erstmals unternehmensweit koordiniert.
Context IV: Dauerhaftes Unternehmen
In etablierten Organisationen wird Architektur zu einer eigenen organisatorischen Funktion.
Typische Strukturen:
-
Architecture Office
-
Enterprise Architecture Practice
-
Architecture Governance
Charakteristisch sind:
-
klar definierte Rollen
-
formale Governance
-
langfristige Transformationsplanung
Hier wird Architektur zu einem zentralen Instrument der Unternehmenssteuerung.
Fazit
Rollen im Enterprise Architecture Management lassen sich auf unterschiedliche Weise definieren. Während Frameworks wie TOGAF konkrete Rollen vorschlagen, zeigt das Zachman Framework vor allem unterschiedliche Perspektiven auf Architektur.
Eine systematische Herleitung von Rollen gelingt, wenn man Architektur entlang grundlegender Fragen strukturiert – etwa über die sechs Perspektiven:
-
Was
-
Wie
-
Womit
-
Weshalb
-
Wann
-
Wer
Diese Fragen machen sichtbar, welche Verantwortlichkeiten im Architekturraum überhaupt existieren.
Welche Rollen tatsächlich etabliert werden, hängt jedoch stark vom organisatorischen Kontext ab. Mithilfe der Skalierungsstufen des DPBoK lässt sich nachvollziehen, wie Architekturrollen von einer einzelnen Person bis hin zu einer institutionalisierten Architekturorganisation wachsen können.
Damit wird deutlich:
EAM-Rollen sind kein starres Set von Titeln, sondern ein skalierbares Organisationskonzept für Architekturverantwortung.
Once-Only in Dokumentationen
Was ist das Once-Only-Prinzip?
Das Once-Only-Prinzip besagt: Daten oder Informationen sollen nur einmal erfasst, gespeichert und gepflegt werden – und an allen relevanten Stellen wiederverwendet werden. Es vermeidet Redundanz, minimiert Fehlerquellen und reduziert Wartungsaufwand. Ursprünglich aus der Verwaltung und dem E-Government bekannt, gewinnt es auch in technischer Dokumentation zunehmend an Bedeutung – besonders in komplexen, agilen und skalierbaren Systemen.
Warum ist Once-Only in Dokumentationen wichtig?
In Softwareprojekten wachsen Dokumentationen oft unkoordiniert:
- API-Dokumentationen existieren separat von Benutzerhandbüchern.
- Diagramme werden manuell gezeichnet und nicht mit Code synchronisiert.
- Konfigurationshinweise werden in mehreren Dokumenten dupliziert.
Das führt zu Inkonsistenzen, veralteten Inhalten und erhöhtem Pflegeaufwand. Once-Only schafft hier Klarheit:
Einmal schreiben. Überall nutzen.
Documentation Engineering: Die Grundlage für Once-Only
Documentation Engineering ist die systematische, ingenieurmäßige Herangehensweise an Dokumentation – mit Fokus auf Struktur, Wiederverwendbarkeit und Automatisierung. Es ermöglicht:
- Modulare Dokumente: Inhalte werden in wiederverwendbare Bausteine (z. B. „Komponentenbeschreibungen“, „Fehlercodes“) zerlegt.
- Zentrale Quellen: Alle Inhalte stammen aus einer einzigen, gepflegten Quelle (Single Source of Truth).
- Automatisierte Verknüpfung: Inhalte werden dynamisch in verschiedene Ausgabeformate (PDF, Web, Help-Systeme) übersetzt.
Beispiel:
Ein API-Endpunkt wird in einer YAML-Datei beschrieben. Diese dient als Quelle für:
- Swagger/OpenAPI-Dokumentation
- Benutzerhandbuch-Abschnitte
- Entwickler-Referenz
- Automatisierte Tests
→ Keine manuelle Kopie. Keine Inkonsistenz. Nur eine Quelle.
Docs-as-Ecosystem: Dokumentation als lebendiges System
Ein Docs-as-Ecosystem versteht Dokumentation nicht als statisches Artefakt, sondern als integriertes, dynamisches System, das mit Code, Tests, CI/CD und Monitoring verbunden ist.
Merkmale eines Docs-as-Ecosystem:
- Automatische Generierung: Dokumentation wird aus Code-Kommentaren, Konfigurationsdateien oder Tests generiert.
- Feedback-Schleifen: Nutzer können direkt aus der Dokumentation Feedback geben – z. B. über „War diese Information hilfreich?“-Buttons.
- Versionierung: Dokumentation wird mit dem Code versioniert – keine Diskrepanzen zwischen Version 1.2 und der dazugehörigen Dokumentation.
- Suchbarkeit & Navigation: Inhalte sind über Suchmaschinen und intelligente Navigation verknüpft – nicht nur linear lesbar.
Wirkung auf Once-Only:
Jeder Inhalt ist Teil eines Netzwerks. Änderungen an einer Stelle wirken sich automatisch auf alle abhängigen Dokumente aus – ohne manuelle Nachpflege.
Diagrams-as-Code: Visualisierungen als Code
Diagramme sind oft die größte Quelle für Redundanz:
- Ein Architekturdiagramm wird in PowerPoint erstellt, dann in Confluence eingefügt, dann in ein PDF kopiert.
- Bei Änderungen muss es überall manuell aktualisiert werden.
Lösung: Diagrams-as-Code
Mit Tools wie Mermaid, PlantUML, Graphviz oder Diagrams.net (mit Code-Export) werden Diagramme als Text definiert – und können in die Dokumentation integriert werden.
Beispiel (Mermaid):
graph TD
A[Benutzer] --> B[API-Gateway]
B --> C[Auth-Service]
B --> D[Order-Service]
C --> E[DB]
D --> E
→ Dieser Code kann in Markdown, Sphinx, Docusaurus oder andere Systeme eingebettet werden.
→ Änderungen am Code aktualisieren automatisch das Diagramm in allen Dokumenten.
→ Keine manuelle Pflege. Keine veralteten Grafiken.
Docs-as-Code: Die technische Umsetzung von Once-Only
Docs-as-Code ist die Praxis, Dokumentation wie Software zu behandeln:
- In Git versioniert
- Mit CI/CD automatisiert
- Mit Tests validiert
- Mit Pull Requests gepflegt
Wichtige Elemente:
- Quellcode-Repositories: Dokumentation liegt im selben Repo wie der Code – oder in einem dedizierten, aber verknüpften Repo.
- Automatisierte Builds: Bei jeder Änderung wird die Dokumentation neu generiert und veröffentlicht.
- Validierung: Links werden geprüft, Syntax wird validiert, Diagramme werden gerendert.
- Wiederverwendung: Mit Include- oder Import-Mechanismen werden Bausteine in mehreren Dokumenten wiederverwendet.
Beispiel mit Antora (AsciiDoc):
.. include::requirements.adoc
Änderungen an requirements.adoc wirken sich auf alle Dokumente aus, die sie einbinden.
Praktische Umsetzung: Schritt-für-Schritt
-
Identifiziere redundante Inhalte
→ Welche Abschnitte werden mehrfach kopiert? Welche Diagramme existieren in mehreren Versionen? -
Erstelle zentrale Quellen
→ Fasse wiederkehrende Inhalte in wiederverwendbaren Dateien zusammen (z. B.shared/,components/). -
Wähle Tools, die Docs-as-Code und Diagrams-as-Code unterstützen
→ Markdown + Mermaid (oder AsciiDoc + PlantUML) + Git + CI/CD (z. B. GitHub Actions, GitLab CI). -
Integriere Dokumentation in den Entwicklungsprozess
→ Jede Codeänderung, die die API betrifft, erfordert eine Dokumentationsänderung – als Teil des Pull Requests. -
Automatisiere Validierung und Veröffentlichung
→ Prüfe Links, Syntax, Diagramme. Veröffentliche automatisch auf einer Dokumentations-Website. -
Etabliere Feedback-Mechanismen
→ Nutzer können direkt aus der Dokumentation Feedback geben – z. B. über GitHub Issues oder integrierte Formulare.
Fazit: Once-Only ist kein Luxus – es ist notwendig
In einer Welt, in der Software ständig wächst und sich ändert, ist manuelle Dokumentation nicht mehr tragbar. Once-Only ist die Antwort:
- Effizienz: Weniger Arbeit, weniger Fehler.
- Konsistenz: Alle Nutzer sehen denselben, aktuellen Stand.
- Skalierbarkeit: Dokumentation wächst mit dem System – ohne zusätzlichen Aufwand.
Mit Documentation Engineering, Docs-as-Ecosystem und Docs-as-Code wird Once-Only nicht nur möglich – es wird zur Grundlage einer modernen, lebendigen Dokumentation.
Mehrere Wege einen Datenfluss zu modellieren
Daten- oder Informationsfluss?
Der Datenfluss beschreibt die Übertragung von rohen, unverarbeiteten Daten, unabhängig ihrer fachlichen Bedeutung.
Beim Informationsfluss geht es hingegen um die Übertragung von verarbeiten bzw. interpretierten Daten, die für den Empfänger einen klaren und erkennbaren Nutzen haben.
Natürlich ist es IT-Umfeld so, dass wenn Informationen transferiert werden müssen, dies auf Basis eines Datentransfers geschieht. Der Datenfluss bildet die technische Grundlage für den Informationsfluss.
Die in diesem Artikel beschriebenen Darstellungsformen verwenden Elemente von beiden Varianten, jedoch steht der Sinn und Zweck des Informationsflusses im Vordergrund.
Das verwendete Beispiel
Als Beispiel dient uns ein Rechnungsversand mittels EDI. Die Abteilung “Rechnungswesen” sendet Rechnung im XML-Format über eine zentrale Middleware an mehrere (in diesem Fall drei) Kunden.
Folgende weitere Parameter sind bekannt:
| Parameter | Wert |
|---|---|
| Datenquelle | CRM d. Marketing (für Adressdaten) ERP d. Verkaufs (für Rechnungsdaten) |
| Sender | Rechnungswesenabteilung |
| Quellsystem | Finanzmodul |
| Empfänger | Kunde |
| Geschäftsobjekt | Monatsrechnung |
| Datenobjekt | PDF-Datei |
| Versand-Technologie | SFTP |
| Intervall | Monatlich |
flowchart LR
CRM[CRM]
VM[ERP]
FM[Finanzmodul]
R(Rechnung)
MW{Middleware}
FTP{SFTP}
K[Kunde]
CRM --> FM
VM --> FM
FM --> R --> MW
MW --> FTP
FTP --> K
Mit einem einfachen Flussdiagramm lässt sich diese Interaktion recht einfach darstellen, doch fehlen einige Informationen. Oder besser gesagt, sie lassen sich nicht so einfach in übersichtlicher Form darstellen. Die unterschiedlichen Ebenen (Geschäft, Anwendung, Infrastruktur) sind nicht klar differenziert, auch der zeitliche Aspekte (monatlich) fehlt.
Verschiedene Standards der Modellierung
Es gibt mehrere Standards, welche die Modellierung von Informationsflüssen unterstützen
Archimate
Als Modellierungssprache für Unternehmensarchitekturen ist Archimate sehr gut für die Darstellung von Informationsflüssen geeignet. Aufgrund der Ebenen-Strategie lässt sich auch der Übergang vom Daten- zum Informationsfluss darstellen.

Vorteile
- dank den Architektur-Ebenen lassen sich Informationsfluss, Datenfluss und die benötigte Infrastruktur darstellen.
- je nach eingesetztem Tool, lassen sich die einzelnen Elemente mit Portfolio-Einträgen verknüpfen, bzw. anhand von Portfolio-Einträgen generieren.
Nachteile
- Archimate ist ausschliesslich menschenlesbar, nicht maschinenlesbar
- Wer die Archimate-Syntax nicht kennt, kann sich mit der Interpretation schwer tun
- ohne klare Modellierungsrichtlinien können Modelle eher chaotisch wirken, man kann sich in mögliche Details verlieren.
- Es gibt keine spezifischen Elemente für zeitliche Aspekte, diese müssten mittels Notizen als Beschreibung hinzugefügt werden.
UML
UML kennt keinen eigenen Diagrammtyp für Informationsflüsse, jedoch finden sich in der Gruppe der Verhaltensdiagramme mehrere geeignete Diagrammarten. Für diesen Artikel wenden wir das Sequenzdiagramm an.
sequenceDiagram participant Marketing as Marketing-Abteilung participant CRM as CRM-System participant Verkauf as Verkaufsabteilung participant ERP as ERP-System participant Finanz as Finanzmodul participant MW as Middleware participant FTP as Kunden-FTP participant Kunde Note over Finanz: Trigger am 1. des Monats Marketing->>CRM: Pflege Adressdaten Verkauf->>ERP: Pflege Produktdaten Finanz->>CRM: Anfrage Adressdaten CRM-->>Finanz: Adressdaten Finanz->>ERP: Anfrage Produktdaten ERP-->>Finanz: Produktdaten Finanz->>Finanz: Monatsrechnung erzeugen Finanz->>Finanz: PDF-Rechnung generieren Finanz->>MW: Übergabe PDF-Rechnung MW->>FTP: Ablegen PDF-Datei Kunde->>FTP: Abruf PDF-Rechnung
Vorteile
- sehr strukturierte Darstellung, Teilnehmer klar sichtbar
- zeitlicher Ablauf der Aktionen sehr übersichtlich
- Rückantworten / Reaktionen auch klar darstellbar
Nachteile
- schnell unübersichtlich, man sollte sich auf Informations- oder Datenfluss konzentrieren, nicht beides gemischt
BPMN
BPMN gilt als Standard im Geschäftsprozessmanagement und wird von vielen Software-Werkzeugen unterstützt.
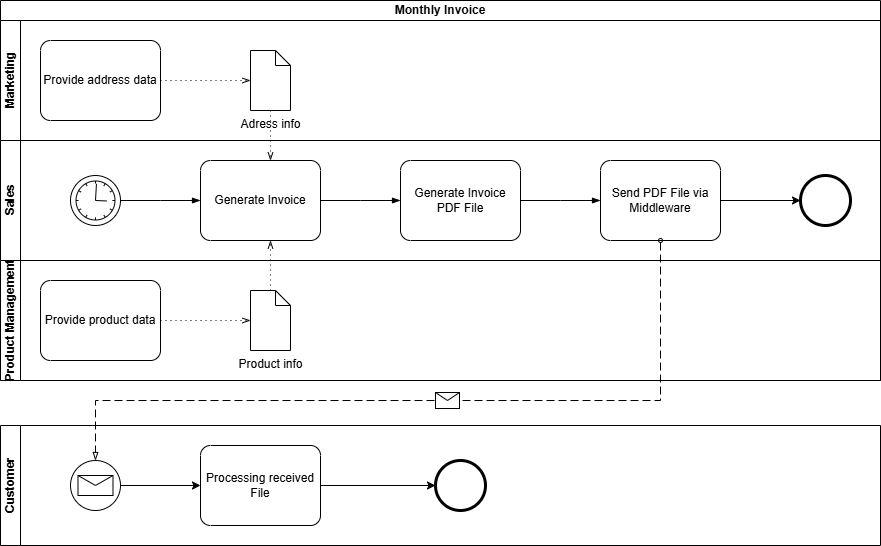
Vorteile
- Mittels Pools und Lanes lassen sich die Teilnehmer am Informationsfluss strukturiert und übersichtlich darstellen. Auch komplexere Informationsflüsse mit z.B. mehreren Empfängern lassen sich einfach umsetzen
- Mittels Ereignis-Meldungen lassen sich Intervalle bzw. zeitlichen Ausführungspunkte deutlich darstellen.
- Ein BPMN-Modell ist mittels einer BPM-Engine auch maschinenlesbar bzw. ausführbar
Nachteile
- Um die Infrastruktur und die Architektur rund um den Informationsfluss darzustellen, fehlen BPMN die notwendigen spezifischen Darstellungs-Elemente
Fazit und persönliche Empfehlung
Alle drei Notationen – UML-Sequenzdiagramme, BPMN und ArchiMate – bieten wertvolle Ansätze für die Modellierung von Informationsflüssen und Architekturen. Doch aus meiner Perspektive ragt ArchiMate heraus: Es ist die vielseitigste Sprache und besonders geeignet, um das Zusammenspiel der architektonischen Ebenen im EAM abzubilden – von der Strategie über die Geschäftsprozesse bis hin zur Technologie.
ArchiMate ermöglicht es, nicht nur Sequenzflüsse oder Prozesse (wenn auch nicht so detailliert wie UML oder BPMN), sondern vor allem Architekturabhängigkeiten und -zusammenhänge darzustellen. Diese ganzheitliche Sicht ist entscheidend, um komplexe Unternehmensarchitekturen zu verstehen und zu steuern. Während BPMN und UML-Sequenzdiagramme in ihren Spezialgebieten – Prozesse bzw. Interaktionen – überlegen sind, bietet ArchiMate die notwendige Flexibilität, um mit einer einzigen Notation alle Ebenen abzubilden.
Meine Empfehlung:
- Für Unternehmen mit begrenzten Ressourcen (z. B. kleinere oder mittelgroße Organisationen) ist ArchiMate die pragmatischste Wahl, da es die meisten Anforderungen abdeckt, ohne auf mehrere Notationen angewiesen zu sein.
- Bei vorhandenen Kapazitäten lohnt sich ein spezialisierte Einsatz der Sprachen: BPMN für detaillierte Prozessmodellierung, UML-Sequenzdiagramme für technische Interaktionen und ArchiMate als übergeordnetes Framework, das alles zusammenführt.
ArchiMate ist somit nicht nur eine Notation, sondern ein Schlüsselwerkzeug, um die Komplexität moderner Enterprise-Architekturen zu beherrschen – ohne dabei die Übersicht zu verlieren.
Portfolios in EAM
Von EVA zu EAM – wie sich Architekturportfolios aus einfachen Fragen ableiten lassen
Das EVA-Prinzip (Eingabe – Verarbeitung – Ausgabe) beschreibt ein grundlegendes Muster der Informationsverarbeitung.
Es ist bewusst einfach gehalten und genau deshalb universell einsetzbar – weit über technische Systeme hinaus.
Überträgt man dieses Denkmodell auf Enterprise Architecture Management (EAM), entsteht eine überraschend klare Logik: Aus EVA lassen sich grundlegende Leitfragen ableiten, die wiederum direkt zu den bekannten Architekturportfolios führen.
EVA als Ausgangspunkt
Im Kern beschreibt EVA drei Aspekte:
- Eingabe – welche Informationen liegen vor?
- Verarbeitung – was geschieht mit diesen Informationen?
- Ausgabe – welche Ergebnisse entstehen?
Auf Architekturarbeit übertragen ergeben sich daraus zunächst drei zentrale Fragen:
- Welche Informationen sind relevant?
- Wie werden diese Informationen verarbeitet?
- Womit wird diese Verarbeitung umgesetzt?
Diese drei Fragen bilden den inhaltlichen Kern der Betrachtung.
Sie beschreiben, was betrachtet wird und wie Informationsverarbeitung grundsätzlich funktioniert.
In der Praxis zeigt sich jedoch schnell:
Für tragfähige Architekturentscheidungen reicht diese Sicht allein nicht aus.
Architektur existiert nicht isoliert, sondern:
- in Organisationen,
- mit einem bestimmten Zweck,
- und über einen längeren Zeitraum hinweg.
Deshalb müssen die drei Kernfragen um weitere Perspektiven ergänzt werden, die Kontext, Verantwortung und Zeit berücksichtigen.
Aus dieser Erweiterung ergeben sich drei zusätzliche Leitfragen:
- Wer trägt Verantwortung?
- Warum wird etwas so gestaltet?
- Wann ist etwas relevant oder gültig?
Gemeinsam bilden diese sechs Leitfragen eine vollständige, aber dennoch einfache Grundlage, um Unternehmensarchitekturen systematisch zu erschliessen.
Die abgeleiteten Leitfragen
Aus dem EVA-Denken ergeben sich somit sechs grundlegende Leitfragen:
1. Welche Informationen sind relevant?
Diese Frage entsteht direkt aus der Eingabe-Perspektive.
Sie bildet die Grundlage für:
- fachliche Objekte
- Informationen
- Datenstrukturen
- Datenflüsse
Zugeordnetes Portfolio:
Information / Data Portfolio
2. Wie werden Informationen verarbeitet?
Diese Frage leitet sich aus der Verarbeitung ab.
Sie beschreibt:
- fachliche Abläufe
- Geschäftsregeln
- Funktionen und Services
- deren Umsetzung in Anwendungen
Zugeordnetes Portfolio:
Business & Application Portfolio
3. Womit wird die Verarbeitung umgesetzt?
Auch diese Frage ist Teil der Verarbeitung, jedoch mit Fokus auf die Mittel.
Sie adressiert:
- Technologien
- Plattformen
- Infrastruktur
- technische Standards
Zugeordnetes Portfolio:
Technology / Infrastructure Portfolio
4. Wer ist verantwortlich?
Diese Frage ergänzt EVA um die organisatorische Dimension.
Sie klärt:
- Rollen
- Zuständigkeiten
- Ownership
Zugeordnetes Portfolio:
Organisation / Capability Portfolio
5. Warum wird etwas so gestaltet?
Diese Frage stellt den Zweck her.
Sie bezieht sich auf:
- Ziele
- Prinzipien
- strategische Treiber
- Nutzenargumentation
Zugeordnetes Portfolio:
Strategy / Motivation Portfolio
6. Wann ist etwas relevant?
Diese Frage bringt die Zeitdimension ein.
Sie beschreibt:
- zeitliche Gültigkeit
- Übergänge
- Abhängigkeiten
- Lebenszyklen
Zugeordnetes Portfolio:
Roadmap / Lifecycle Portfolio
Grafische Einordnung
Die folgende Darstellung zeigt, wie sich die Leitfragen logisch aus dem EVA-Prinzip ableiten und den jeweiligen Portfolios zuordnen lassen:
flowchart TB
EVA["EVA Principle<br/>Input · Processing · Output"]
Q1["Which information?"]
Q2["How is it processed?"]
Q3["With which means?"]
Q4["Who is responsible?"]
Q5["Why is it done this way?"]
Q6["When is it relevant?"]
EVA --> Q1
EVA --> Q2
EVA --> Q3
Q1 --> P1["Information / Data Portfolio"]
Q2 --> P2["Business & Application Portfolio"]
Q3 --> P3["Technology Portfolio"]
Q4 --> P4["Organisation / Capability Portfolio"]
Q5 --> P5["Strategy / Motivation Portfolio"]
Q6 --> P6["Roadmap / Lifecycle Portfolio"]
Die Grafik zeigt keine Hierarchie, sondern eine gedankliche Ableitung:
-
EVA liefert das Grundmuster
-
die Leitfragen erschliessen den Kontext
-
die Portfolios strukturieren die Inhalte
Gemeinsamkeiten und Abhängigkeiten
In der Praxis existieren diese Portfolios nicht isoliert:
-
Ohne Klarheit über Informationen bleiben Prozesse und Systeme unscharf.
-
Ohne Verständnis der Verarbeitung fehlt der Zusammenhang zwischen Business und IT.
-
Ohne geeignete Technologie können Anforderungen nicht umgesetzt werden.
-
Ohne definierte Verantwortung ist Wissen nicht nachhaltig.
-
Ohne strategischen Zweck fehlt die Legitimation.
-
Ohne Zeitbezug ist keine Steuerung möglich.
Die Leitfragen wirken dabei als verbindendes Element zwischen den Portfolios.
Fazit
Das EVA-Prinzip zeigt, wie Informationsverarbeitung grundsätzlich funktioniert.
Leitet man daraus einfache Leitfragen ab und ordnet sie den bekannten EAM-Portfolios zu, entsteht eine klare und verständliche Struktur für Architekturarbeit.
Der Mehrwert liegt nicht in neuen Frameworks, sondern in der konsequenten Anwendung einfacher Fragen:
Gute Architekturarbeit beginnt dort,
wo Zusammenhänge verstanden werden –
nicht dort, wo zusätzliche Komplexität entsteht.
Manchmal reicht es, das Bekannte neu zu ordnen.
EVA-Prinzip im Zusammenhang mit EAM
Was ist das EVA-Prinzip?
Unter dem EVA-Prinzip (engl. IPO-model) versteht man das Grundprinzip der Datenverarbeitung, wobei die drei Buchstaben für Eingabe (Input), Verarbeitung (Processing) und Ausgabe (Output) stehen.
Diese drei Begriffe beschreiben die grundlegende Logik der Informationsverarbeitung.
flowchart LR id1(Eingabe) --> id2(Verarbeitung) --> id3(Ausgabe) style id1 fill:#ffff00,stroke:#333,stroke-width:2px style id2 fill:#00ffff,stroke:#333,stroke-width:2px style id3 fill:#ffff00,stroke:#333,stroke-width:2px
Im klassischen Sinne wird auf die physischen Komponenten, also die Hardware, hingewiesen:
| Eingabe | Verarbeitung | Ausgabe |
|---|---|---|
| Tastatur Maus Touchpad Joystick Scanner Barcode-/QR-Code-Leser |
Hauptprozessor CPU Chipsatz Controller |
Monitor Display Lautsprecher Beamer Drucker Plotter |
Aber das Prinzip ist viel universeller einsetzbar, als nur für physische Informatik-Komponenten.
Wo lässt es sich noch anwenden?
Das EVA-Prinzip lässt sich in jedem nur erdenklichen Bereich anwenden. Jede Interaktion, jeder Prozess lässt sich damit abbilden.
Denn jede Interaktion, also selbst ein simpler Dialog zwischen zwei Menschen, nimmt Informationen entgegen, verarbeitet sie und erzeugt eine Antwort.
Als Beispiel ein kurzer Dialog bzgl. des Wohlbefindens aus Sicht des Befragten:
flowchart LR id1(Hört 'Wie geht es Dir?') --> id2(Verarbeitet Frage, denkt über Antwort nach) --> id3(Antwortet 'Sehr gut, danke.') style id1 fill:#ffff00,stroke:#333,stroke-width:2px style id2 fill:#00ffff,stroke:#333,stroke-width:2px style id3 fill:#ffff00,stroke:#333,stroke-width:2px
Jede Situation oder jeder Vorgang kann auf die drei Schritte Informationsaufnahme, Informationsverarbeitung und Informationsausgabe heruntergebrochen werden.
Das EVA-Prinzip im EAM
Um das EVA-Prinzip nachhaltig auf Unternehmensarchitekturen zu übertragen, müssen die Elemente noch durch grundsätzliche Fragen abgesichert werden.
- Was (welche Quellinformationen) benötige ich, um den Vorgang zu starten bzw. starten zu können?
- Was (Welche Zielinformationen) benötige ich zum Abschluss des Vorganges?
- Wie (nach welchen Regeln) wandle ich die Quell- in Zielinformationen um?
Mit diesen Fragen wird das klassische EVA-Prinzip abgehandelt, für Architekturen muss noch folgende Frage zwingend gestellt werden:
- Womit (mit welchen Mitteln) erreiche ich das?
Die Fragen des Was und Wie werden grundsätzlich in der Geschäftsebene abgehandelt, da diese vor allem den fachlichen Prozess ansprechen.
Das Womit wird von der Technikebene (durch die Infrastruktur) zur Verfügung gestellt.
Die Informationssystemebene (oder auch Anwendungs- bzw. Applikationsebene genannt) dient als Vermittler/Übersetzer und sorgt für eine reibungslose Unterstützung des Fachbereichs durch die IT. Somit wird der Sinn und Zweck von Unternehmensarchitekturen erfüllt.
flowchart TD id1(Geschäftsarchitektur) <--Was? Wie?--> id2(Informationssystemarchitektur) <--Womit?--> id3(Technische Architektur) style id1 fill:#ffff00,stroke:#333,stroke-width:2px style id2 fill:#00ffff,stroke:#333,stroke-width:2px style id3 fill:#00ff00,stroke:#333,stroke-width:2px
Zu den Grundfragen Was, Wie und Womit kommen noch folgende Ergänzungsfragen:
- Weshalb ist dies notwendig? (Sinn und Zweck)
- Wann (Bis wann) benötigt man dies? (Zeitlicher Rahmen)
- Wer ist dafür zuständig? (Verantwortlichkeit)
Die Ergänzungsfragen sind bewusst sehr allgemein gehalten, da sie punktuell an jeder Stelle des Vorganges angesetzt werden können.
| WESHALB | WANN | WER | |
|---|---|---|---|
| WAS | Wozu werden die Quell-/Zielinformationen benötigt? | Wann/In welchem Zeitraum werden die Quell-/Zielinformationen benötigt? | Wer ist für die Quell-/Zielinformationen verantwortlich? (Dataowner) |
| WIE | Weshalb müssen die Informationen verarbeitet werden? | Wann/In welchem Zeitraum müssen die Informationen verarbeitet werden? | Wer ist für die Verarbeitung bzw. den Verarbeitungsprozess verantwortlich? (Processowner) |
| WOMIT | Wie wird der Einsatz des benötigten Tools begründet? | Wann wird welches Tool benötigt/eingesetzt? | Wer ist für die benötigten Tools verantwortlich? |
Fazit
Wer sich schon länger mit Enterprise Architecture Management befasst hat und auch Einblick in das ein oder andere Framework hatte, dem werden die Fragestellungen nicht neu sein.
Das Zachman Framework kennt ebenso sechs Perspektiven, die mit Fragewörtern identifiziert werden, hierzu gehören Was (Daten), Wie (Funktion), Wo (Netzwerk), Wer (Personen), Wann (Zeit) und Warum (Motivation). Einziger Unterschied zu meiner Darstellung, ich habe statt dem Wo ein Womit. Der Grund dafür ist recht einfach zu erklären. In der heutigen Welt sind wir so digitalisiert und vernetzt unterwegs, dass das physische Wo nur noch eine untergeordnete oder fast schon gar keine Rolle mehr spielt. Wichtiger sind heutzutage die eingesetzten Werkzeuge, eben das Womit.
In meiner Darstellung habe ich mich auch an TOGAF orientiert, wo die Fragestellungen nicht explizit so erwähnt, aber über die angebotenen Architekturebenen abgedeckt werden:
- Geschäftsarchitektur: Beschreibt die “Wer”- und “Warum”-Aspekte (z. B. Organigramme, Ziele, Prinzipien).
- Datenarchitektur: Fokussiert auf das “Was” (z. B. Datenmodelle, Datenflüsse).
- Anwendungsarchitektur: Behandelt das “Wie” (z. B. Anwendungslandkarten, Schnittstellen).
- Technologiearchitektur: Adressiert das “Womit” (z. B. Infrastruktur, Netzwerke, Standorte).
Meine Darstellung von EVA im Bezug auf EAM stellt somit keine komplette Neuinterpretation dar, sondern soll mehr aus der Sicht eines pragmatischen Zugangs zeigen, wie es sich anwenden lässt.
Neuigkeiten
ProBase ist nun Beta
ProBase ist nun Beta!
ProBase erreicht den Beta-Status
Ich habe zwar noch nicht alle Inhaltziele für diesen Schritt erreicht, da ich auch schon einige Downloads zur Verfügung stellen wollte. Aber die wichtigsten Docs-Artikel sind erstellt und ich konnte den Blog-Rhythmus von 2 Wochen einhalten.
Auch sollte bei der Bedienung der Seite kein Fehler mehr auftreten, auch wenn noch nicht alle Funktionen freigeschalten sind.
Weitere Schritte
Die nächsten 4 Monate (bis zum Produktiv-Start am 16.07.2026) wird nun “Gas” gegeben :-)
Warum mache ich ProBase?
Wofür steht der Name “ProBase”?
Der Name ProBase hat nostalgische Gründe und zwar war ich Anfang der 2000er Jahre selbstständig, meine Firmenwebseite lief unter “probase.at” (ich lebte damals noch in Österreich). Der Name entstand aus einer Brainstorming-Session heraus. Ich wollte damals vor allem Dienstleistungen rund um Software-Entwicklung und Datenbanken anbieten. Aus den Begriffen Programming und Database entstand schliesslich “ProBase”. Mir gefiel der Name aber auch aus dem Grund, dass er als “professional Base” interpretiert werden konnte. Aus einer Laune heraus habe ich dann - mittlerweile in der Schweiz wohnhaft - in Anlehnung an diese Vergangenheit “probase.ch” registriert, ohne einen Sinn und Zweck dafür zu haben. “Programming” und “Database” passen heute nicht mehr, trotzdem gefällt mir der Name nachwievor und ich wollte ihn sinnvoll nutzen.
Grund für den Start von ProBase
Grundsätzlich dient die Webseite zum Selbstzweck. Ich möchte mein Wissen rund um Unternehmensarchitekturen und Dokumentationen erweitern und habe nach einer Möglichkeit gesucht, das alles in einer strukturierten Art und Weise zu sammeln. Natürlich gibt es viele nützliche Tools zur lokalen Installation, um Wissen zu sammeln und zu sortieren. Doch gleichzeitig wollte ich selbst auch etwas technischer vorgehen und Auszeichnungssprachen wie Markdown und AsciiDoc ausprobieren, als auch Werkzeuge, mit denen ich diese verwenden kann. Markdown wird - neben Wikis - auch gern für sogenannte Static Site Generators genutzt. Hugo gefiel mir so sehr, dass ich unbedingt eine Webseite damit machen wollte. So war die Idee bzw. der Sinn und Zweck für die Domain probase.ch geboren.
Warum dreisprachig?
Nun, ich bin selbst zweisprachig (deutsch/französisch) aufgewachsen und möchte dem Rechnung tragen, dazu kommt eben noch englisch. Aber auch in der Schweiz passt das sehr gut. Es gibt sogar die Idee, die Seite noch auf Italienisch zu übersetzen, aber dafür muss ich die Sprache noch lernen ;-)
ProBase ist eröffnet, zumindest als Alpha-Version
Was ist ProBase genau?
ProBase soll einen Blog und praktische Ressourcen zu den Themen Enterprise Architecture Management und Documentation Engineering bieten.
Einteilung der Webseite
Blog
In diesem Bereich teile ich selbst erfasste Artikel (teils mit Hilfe von KI) aus diesen Themenbereichen. z.B. Use-Cases, spezifische Tutorials, Meinung zu aktuellen Entwicklungen usw… In der Regel sollte jeden 2. Samstag ein neuer Artikel veröffentlicht werden.
Docs
Dieser Bereich wird zum Start der Beta-Phase erst so richtig aktiv. Hier möchte ich kurze Dokumentationen (auch wieder selbst verfasst) zu Frameworks, Werkzeugen, Anwendungen - passend zu den zwei Themenbereichen - anbieten.
Downloads
Hier werde ich - sobald verfügbar - anwendbare Templates, Scripts oder Snippets anbieten.
Guides
Darunter verstehe ich selbst erstellte Guides/Bücher bzw. umfangreichere Dokumentationen, mal sehen was mir dazu alles einfällt ;-)
Courses
In diesem Bereich möchte ich interaktive Kurse als Ergänzung zu den Docs bzw. Books erstellen.
Roadmap
Wie jedes Projekt gibt es auch hierfür eine Timeline bzw. Roadmap.
Alpha-Stadium (01.01.26 - 15.03.26)
In diesem Stadium ist nur der Blog von Anfang an verfügbar. Bis zu Beginn des nächsten Stadiums sollen dann bereits einige Docs und Downloads kommen.
Dazu wird noch an der Webseite generell gearbeitet, Bugs behoben, …
Beta-Stadium (16.03.26 - 15.07.26)
Die Bereiche Docs und Downloads werden erweitert, dazu sollen erste Einträge im Bereich “Courses” dazukommen.
Technisch sollte die Webseite keine Fehler mehr enthalten.
Produktiv (ab 16.07.26)
Ab da soll dann der letzte Bereich (Books) verfügbar sein und es werden dann laufend neue Artikel, Docs, Downloads, Courses und Books erstellt und veröffentlicht.